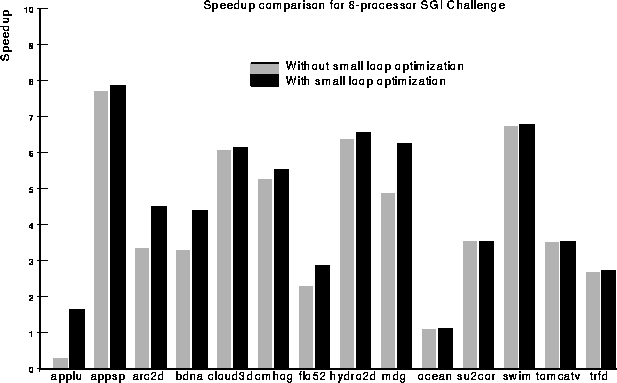
As a first step, the runtime overheads of small loops, which have larger execution time in parallel than in serial, has been analyzed. The goal is to find the thresholds, which are used to select the loops with larger speedup when it runs in parallel than in serial. This covers static performance prediction, optimization ordering, scheduling, analyzing cache effects in source level, reducing runtime overheads, etc. This optimization has been implemented on Polaris parallelizing optimizing compiler.The compiler switch, strategy=3, is used for this optimization when compiling source programs.