Our main focus since the begining of the Polaris project in 1993 has been on accurately identifying parallelism. Even without additional efforts, Polaris has been quite successful in bus-based shared memory machines. However, in order to increase Polaris' repertoire directive languages, some of our recent new efforts go into enhancing Polaris to handle other classes of machines such as scalable shared-memory multiprocessors.
The Cray T3D is a commerical scalable shared memory machine with noncoherent caches. While the lack of cache coherence in the T3D helps make the machine more cost-effective and scalable, it also introduces more difficulties in the parallel programming of the machine than in that of other cache coherent machines such as the Convex Exampler and the SGI Power Challenge. The goal of this project is to develop effective compiler techniques with which the programming difficulties of this noncoherent cache machine are overcomed.
The fundamental strategy we used here is to extend the traditional parallelizing compiler techniques for cache coherent machines to handle the T3D. As a first step, we applied a straightforward translation involving a few optimizations beyond parallelism detection. We take a sequential Fortran 77 program as input and produce the parallelized ouput in the form of CRAFT, an extension of Fortran for the Cray Massively Parallel Processing(MPP) machines. The graph shows the preliminary results with eleven benchmark codes from the Perfect Benchmarks and the SPEC suites.
The two dotted lines in the graph plot the ideal speeds for programs with a parallel coverage of 99% and 90% respectively. After all the eleven programs we analyzed were transformed by Polaris, the parallel coverage was between 90 and 99%. Therefore, the speedups curves for these programs should, under ideal conditions, lie between the two dotted lines. Real program speedups are much lower than the ideal because of overhead, such as communication costs and shared data bypassing the cache. These speedups should improve once we implement optimizations in Polaris to deal with these issues.
One of the most crucial techniques we plan to
explore uses shared memory as a repository of values. In this strategy,
we call the data copying scheme, most
of the work is done on private variables. Before a program section starts,
the processors copy all that is used in the computation from shared memory
into private memory. After a certain amount of work is done, the processors
copy the results back to shared memory so that all processors have access
to the results. Shared memory coherence is maintained by explicit synchronization.
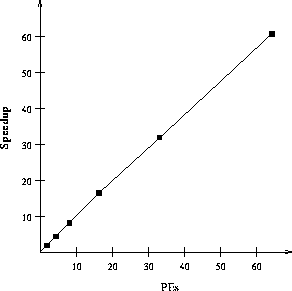
Single-sided communication, in the form of PUT/GET primitives, is used for data copying. The figure at the left shows the speedup of SWIM using PUT/GET that is obtained by hand on up to 64 processors. Using PUT/GET, we conducted similar experiments with other benchmark codes shown in the preliminary experiments. The results have convinced us that the T3D's PUT/GET operations are efficient enough to improve performance across the board.
In addition to the data copying scheme, our long-term objective is to develop and implement more sophisticated techniques such as those necessary for loop scheduling, data distribution, and communication minimization.

 Prof.
Yunheung Paek
Prof.
Yunheung Paek
"On the Parallelization
of Benchmarks on Scalable Shared Memory Multiprocessors,
1998 Proc. International Conference on Parallel Architecures and Compilation
Techniques, Octorber 1998
"Simplification
of Array Access Analysis Patterns for Compiler Optimizations",
1998 ACM SIGPLAN Conference on Programming Language Design and Implementation(PLDI)
, June 1998
"Experimental Study
of Compier Techniques for Scalable Shared Memory Machines",
Proc. 12th IEEE International Parallel Processing Symposium(IPPS) &
9th Symposium on Parallel and Distributed Processing(SPDP), Apr.
1998
"Compiler Techniques
for Effective Communication on Distributed-Memory Multiprocessors", Proc.
1997 International Conference on Parallel Processing(ICPP), Aug.
1997
"Compiling for Scalable
Multiprocessors with Polaris", In PARALLEL PROCESSING LETTERS, World
Scientific Publishing, 1997
"Performance Analysis
for Polaris on Distributed Memory Multiprocessors", 3rd Workshop on
Automatic Data Layout and Performance Prediction, Barcelona, Spain,
Jan. 1997,
"Automatic Parallelization
for Non-cache Coherent Multiprocessors", In Proc. 9th Workshop on Language
and Compilers for Parallel Computing(also to appear in Lecture Notes in
Computer Science, Springer-Verlag
), Aug. 1996
