
|
|
|
Polaris ObjectiveTo advance the state of the art in automatic program parallelization. To create and maintain an optimizing compiler that represents this state of the art and that can be used as a solid infrastructure by compiler research and development groups. The Polaris compiler will include all optimization techniques necessary to transform a given sequential program into a form that runs efficiently on the target machine. This includes techniques such as automatic detection of parallelism and distribution of data. The intended target machines are high-performance parallel computers with a global address space as well as traditional shared-memory multiprocessors. |

The input language includes several directives which allow the user of Polaris to specify parallelism explicitly in the source program. The output language of Polaris is typically in the form of Fortran77 plus parallel directives as well. For example, a generic parallel directive set includes the directives "CSRD$ PARALLEL" and "CSRD$ PRIVATE a,b", specifying that the iterations of the subsequent loop shall be executed concurrently and that the variables a and b shall be declared "private to the current loop", respectively. Another output language that Polaris can generate is the Fortran plus the directive language available on the SGI Challenge machine.
Polaris performs its transformations in several "compilation passes". In addition to many commonly known passes, Polaris includes advanced capabilities performing the following tasks: array privatization, data dependence testing, induction variable recognition, interprocedural analysis, and symbolic program analysis. An extensive set of options allow the user and the developer of Polaris to experiment with the tool in a flexible way. An overview of the Polaris transformations is given in the Publication Automatic Detection of Parallelism: A Grand Challenge for High-Performance Computing.
The implementation of Polaris consists of 170,000 lines of C++ code. A basic infrastructure provides a hierarchy of C++ classes that the developers of the individual compilation passes can use for manipulating and analyzing the input program. This infrastructure is described in the Publication "The Polaris Internal Representation". The Polaris Developer's Guide gives a more thorough introduction for compiler writers.
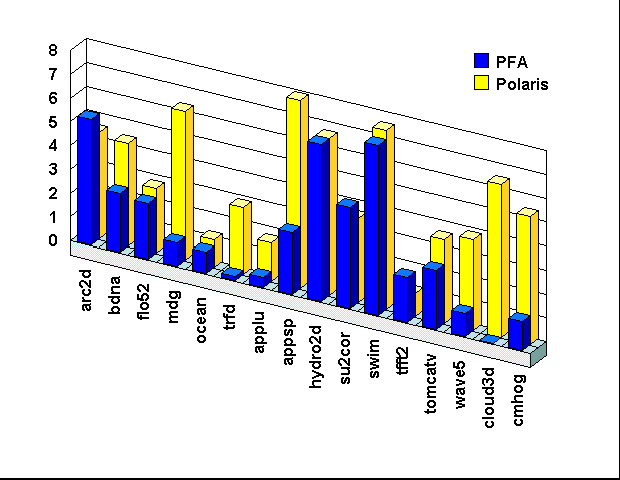
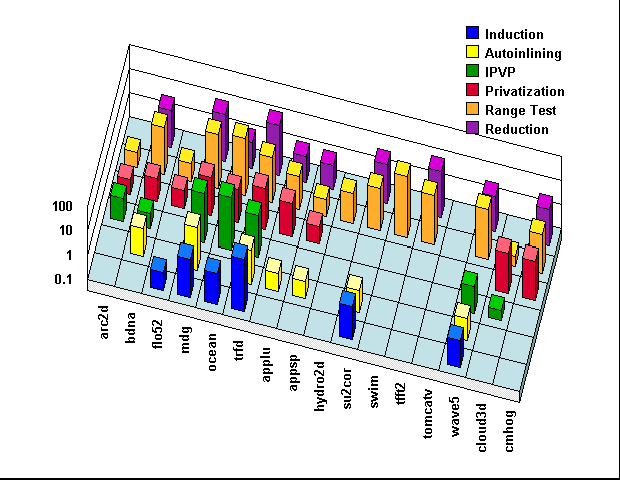
| Program Name | Brief Description | Benchmark Suite | Lines of Code |
|---|---|---|---|
| ARC2D | Fluid dynamics (2D inviscid flows) | Perfect | 4000 | BDNA | Nucleic acid simulation | Perfect | 4000 |
| FLO52 | Fluid dynamics (2D inviscid flow) | Perfect | 2368 |
| MDG | Liquid water simulation | Perfect | 1200 |
| OCEAN | Fluid dynamics (2D Boussinesq fluid layer) | Perfect | 3285 | TRFD | Quantum mechanics | Perfect | 634 |
| TURB3D | 3D turbulent fluid flow | Perfect | 1400 |
| HYDRO2D | Galactical jets simulation | SPEC | 4289 |
| SU2COR | Elementary particle mass computation | SPEC | 2333 |
| SWIM | Shallow water equations | SPEC | 426 |
| TFFT2 | Fourier transforms | SPEC | 642 |
| TOMCATV | Mesh generator | SPEC | 190 |
| CLOUD3D | Weather simulation, | NCSA | 14438 |
| CMHOG | Astrophysical simulation | NCSA | 11826 |
